Pierwsze kroki
Instalacja
Aby zainstalować AlphaCube, otwórz terminal i uruchom następujące polecenie:
pip install -U alphacube
Użycie
Podstawy
Używanie AlphaCube w Pythonie jest proste. Przy pierwszym wywołaniu alphacube.load() wymagane dane modelu zostaną pobrane i zapisane w pamięci podręcznej.
import alphacube
# Załaduj wstępnie wytrenowany model
# Domyślnie "small" na CPU, "large" na GPU
alphacube.load()
# Rozwiąż kostkę na podstawie danego mieszania
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=1024,
)
print(result)
Wynik{
'solutions': [
"D L D2 R' U2 D B' D' U2 B U2 B' U' B2 D B2 D' B2 F2 U2 F2"
],
'num_nodes': 19744, # Całkowita liczba zbadanych węzłów wyszukiwania
'time': 1.4068585219999659 # Czas w sekundach
}
Poprawa jakości rozwiązania
Jeśli chcesz uzyskać krótsze rozwiązania, zwiększ parametr beam_width.
Sprawia to, że wyszukiwanie jest bardziej wyczerpujące kosztem dłuższego czasu obliczeń.
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
Wynik{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'"
],
'num_nodes': 968984,
'time': 45.690575091997744
}
Zezwalanie na kilka dodatkowych ruchów
Możesz uzyskać nie tylko najkrótsze rozwiązania, ale także nieco dłuższe, używając parametru extra_depths.
Instruuje to solwer, aby kontynuował wyszukiwanie po znalezieniu pierwszego rozwiązania.
alphacube.load() # model_id="small"
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
extra_depths=1
)
print(result)
Wynik{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'",
"D R F2 L' U2 R2 U2 R2 B2 U' F B2 D' F' D' R2 F2 U F2 L2", # dodatkowe
"L' D' R' D2 L B' U F2 U R' U' F B' R2 B R B2 F D2 B", # dodatkowe
"R' F L2 D R2 U' B' L' U2 F2 U L U B2 U2 R2 D' U B2 R2", # dodatkowe
"L' U' F' R' U D B2 L' B' R' B U2 B2 L2 D' R2 U' D R2 U2" # dodatkowe
],
'num_nodes': 1100056,
'time': 92.809575091997744
}
Akceleracja GPU
Jeśli masz kompatybilne GPU lub komputer Mac, możesz uzyskać znaczne przyspieszenie, ładując model large.
alphacube.load(model_id="large")
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
Wynik{
'solutions': ["D F L' F' U2 B2 U F' L R2 B2 U D' F2 U2 R D'"],
'num_nodes': 903448,
'time': 20.46845487099995
}
Stosowanie współczynnika ergonomii
Aby znaleźć rozwiązania łatwiejsze do ręcznego wykonania, przekaż słownik ergonomic_bias do metody solve.
Każdemu ruchowi przypisana jest ocena, gdzie wyższe oceny oznaczają bardziej pożądane ruchy. Umożliwia to również szerokie ruchy, takie jak u i r.
ergonomic_bias = {
"U": 0.9, "U'": 0.9, "U2": 0.8,
"R": 0.8, "R'": 0.8, "R2": 0.75,
"L": 0.55, "L'": 0.4, "L2": 0.3,
"F": 0.7, "F'": 0.6, "F2": 0.6,
"D": 0.3, "D'": 0.3, "D2": 0.2,
"B": 0.05, "B'": 0.05, "B2": 0.01,
"u": 0.45, "u'": 0.45, "u2": 0.4,
"r": 0.3, "r'": 0.3, "r2": 0.25,
"l": 0.2, "l'": 0.2, "l2": 0.15,
"f": 0.35, "f'": 0.3, "f2": 0.25,
"d": 0.15, "d'": 0.15, "d2": 0.1,
"b": 0.03, "b'": 0.03, "b2": 0.01
}
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
ergonomic_bias=ergonomic_bias
)
print(result)
Wynik{
'solutions': [
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R U L' U R L",
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R d F' U f F",
"u' U' f' R2 U2 R' L' F' R u2 F2 R2 D2 R u f' l u U"
],
'num_nodes': 1078054,
'time': 56.13087955299852
}
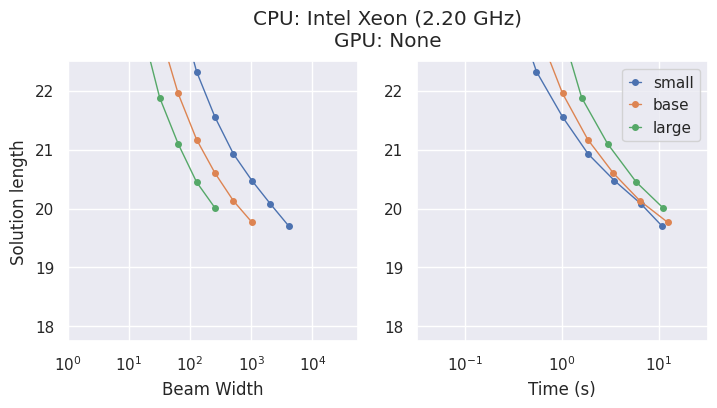
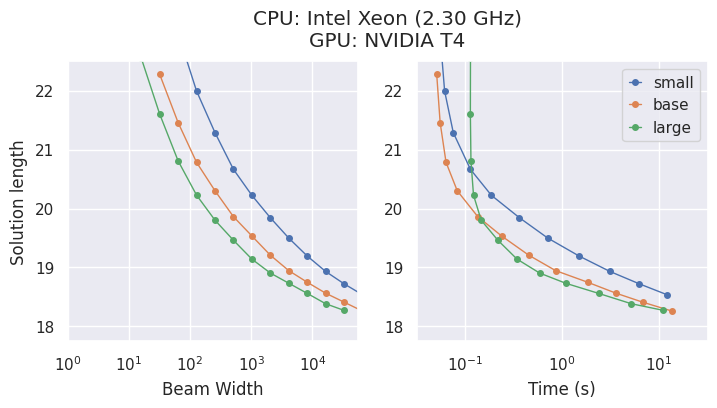
Modele i kompromisy
AlphaCube oferuje trzy optymalnie obliczeniowo wytrenowane modele z oryginalnej publikacji: "small", "base" i "large".
Chociaż większe modele są dokładniejsze, najlepszy wybór zależy od Twojego sprzętu.
- Na CPU, model
"small"jest często najbardziej efektywnym czasowo wyborem. - Na GPU, model
"large"wykazuje najwyższą wydajność i znajduje najlepsze rozwiązania w najkrótszym czasie.
Opcja wiersza poleceń (CLI)
Jeśli wolisz używać alphacube z wiersza poleceń, możesz to zrobić w następujący sposób:
alphacube \
--model_id large \
--scramble "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
--beam_width 100000 \
--extra_depths 3 \
--verbose
Z skróconymi flagami,
alphacube \
-m large \
-s "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
-bw 100000 \
-ex 3 \
-v
Więcej szczegółów znajdziesz w Dokumentacji API > CLI.
Uwaga: Interfejs wiersza poleceń (CLI) ładuje określony model przy każdym uruchomieniu, co sprawia, że jest on najlepiej dostosowany do jednorazowych poleceń, a nie do wielokrotnego rozwiązywania w skrypcie.