快速入门
安装
要安装 AlphaCube,请打开终端并运行以下命令:
pip install -U alphacube
使用方法
基本用法
在 Python 中使用 AlphaCube 非常简单。首次调用 alphacube.load() 时,所需的模型数据将被下载并缓存。
import alphacube
# 加载预训练模型
# 在 CPU 上默认为 "small",在 GPU 上默认为 "large"
alphacube.load()
# 使用给定的打乱公式求解魔方
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=1024,
)
print(result)
输出{
'solutions': [
"D L D2 R' U2 D B' D' U2 B U2 B' U' B2 D B2 D' B2 F2 U2 F2"
],
'num_nodes': 19744, # 探索的总搜索节点数
'time': 1.4068585219999659 # 时间(秒)
}
提高解法质量
如果您想要更短的解法,请增大 beam_width 参数。
这会使搜索更加详尽,但代价是需要更多的计算时间。
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
输出{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'"
],
'num_nodes': 968984,
'time': 45.690575091997744
}
允许额外几步
您不仅可以获得最短的解法,还可以使用 extra_depths 参数获得稍长的解法。
这会指示求解器在找到第一个解法后继续搜索。
alphacube.load() # model_id="small"
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
extra_depths=1
)
print(result)
输出{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'",
"D R F2 L' U2 R2 U2 R2 B2 U' F B2 D' F' D' R2 F2 U F2 L2", # 额外
"L' D' R' D2 L B' U F2 U R' U' F B' R2 B R B2 F D2 B", # 额外
"R' F L2 D R2 U' B' L' U2 F2 U L U B2 U2 R2 D' U B2 R2", # 额外
"L' U' F' R' U D B2 L' B' R' B U2 B2 L2 D' R2 U' D R2 U2" # 额外
],
'num_nodes': 1100056,
'time': 92.809575091997744
}
GPU 加速
如果您有兼容的 GPU 或 Mac,可以通过加载 large 模型获得显著的速度提升。
alphacube.load(model_id="large")
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
输出{
'solutions': ["D F L' F' U2 B2 U F' L R2 B2 U D' F2 U2 R D'"],
'num_nodes': 903448,
'time': 20.46845487099995
}
应用顺手偏好
要找到更易于手动执行的解法,请向 solve 方法提供一个 ergonomic_bias 字典。
每个转动都被赋予一个分数,分数越高表示该转动越理想。这也启用了诸如 u 和 r 这样的宽转。
ergonomic_bias = {
"U": 0.9, "U'": 0.9, "U2": 0.8,
"R": 0.8, "R'": 0.8, "R2": 0.75,
"L": 0.55, "L'": 0.4, "L2": 0.3,
"F": 0.7, "F'": 0.6, "F2": 0.6,
"D": 0.3, "D'": 0.3, "D2": 0.2,
"B": 0.05, "B'": 0.05, "B2": 0.01,
"u": 0.45, "u'": 0.45, "u2": 0.4,
"r": 0.3, "r'": 0.3, "r2": 0.25,
"l": 0.2, "l'": 0.2, "l2": 0.15,
"f": 0.35, "f'": 0.3, "f2": 0.25,
"d": 0.15, "d'": 0.15, "d2": 0.1,
"b": 0.03, "b'": 0.03, "b2": 0.01
}
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
ergonomic_bias=ergonomic_bias
)
print(result)
输出{
'solutions': [
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R U L' U R L",
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R d F' U f F",
"u' U' f' R2 U2 R' L' F' R u2 F2 R2 D2 R u f' l u U"
],
'num_nodes': 1078054,
'time': 56.13087955299852
}
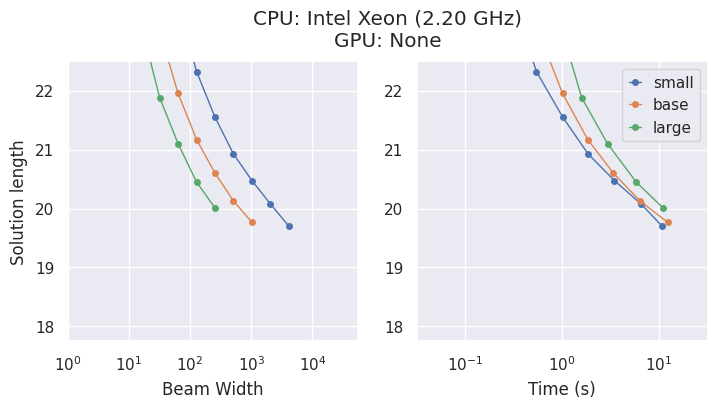
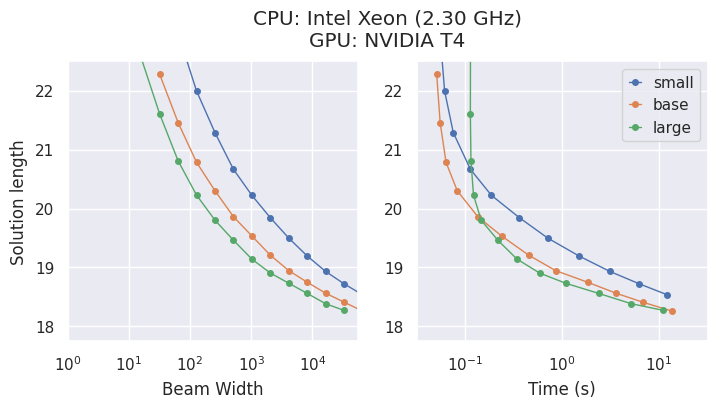
模型与权衡
AlphaCube 提供了来自原始论文的三种计算最优训练模型:"small"、"base" 和 "large"。
虽然更大的模型更准确,但最佳选择取决于您的硬件。
- 在 CPU 上,
"small"模型通常是时间效率最高的选择。 - 在 GPU 上,
"large"模型表现出最高的性能,并能在最短的时间内找到最佳解法。
命令行选项
如果您更喜欢从命令行使用 alphacube,也可以这样做:
alphacube \
--model_id large \
--scramble "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
--beam_width 100000 \
--extra_depths 3 \
--verbose
使用缩写标志,
alphacube \
-m large \
-s "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
-bw 100000 \
-ex 3 \
-v
更多详情请参阅 API 参考 > CLI。
注意: 命令行界面 (CLI) 每次执行都会加载指定的模型,因此它最适合单次使用的命令,而不是在脚本中重复求解。