Primeros Pasos
Instalación
Para instalar AlphaCube, abre una terminal y ejecuta el siguiente comando:
pip install -U alphacube
Uso
Básico
Usar AlphaCube en Python es sencillo. La primera vez que se llama a alphacube.load(), los datos del modelo necesarios se descargarán y se guardarán en caché.
import alphacube
# Carga un modelo pre-entrenado
# Por defecto es "small" en CPU, "large" en GPU
alphacube.load()
# Resuelve el cubo usando una mezcla dada
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=1024,
)
print(result)
Salida{
'solutions': [
"D L D2 R' U2 D B' D' U2 B U2 B' U' B2 D B2 D' B2 F2 U2 F2"
],
'num_nodes': 19744, # Nodos de búsqueda totales explorados
'time': 1.4068585219999659 # Tiempo en segundos
}
Mejorando la Calidad de la Solución
Si quieres soluciones más cortas, aumenta el parámetro beam_width.
Esto hace que la búsqueda sea más exhaustiva a costa de un mayor tiempo de computación.
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
Salida{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'"
],
'num_nodes': 968984,
'time': 45.690575091997744
}
Permitir Unos Pocos Movimientos Extra
Puedes obtener no solo las soluciones más cortas, sino también soluciones ligeramente más largas, usando el parámetro extra_depths.
Esto le indica al solucionador que continúe buscando después de encontrar la primera solución.
alphacube.load() # model_id="small"
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
extra_depths=1
)
print(result)
Salida{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'",
"D R F2 L' U2 R2 U2 R2 B2 U' F B2 D' F' D' R2 F2 U F2 L2", # adicional
"L' D' R' D2 L B' U F2 U R' U' F B' R2 B R B2 F D2 B", # adicional
"R' F L2 D R2 U' B' L' U2 F2 U L U B2 U2 R2 D' U B2 R2", # adicional
"L' U' F' R' U D B2 L' B' R' B U2 B2 L2 D' R2 U' D R2 U2" # adicional
],
'num_nodes': 1100056,
'time': 92.809575091997744
}
Aceleración por GPU
Si tienes una GPU compatible o un Mac, puedes obtener una aceleración significativa cargando un modelo large.
alphacube.load(model_id="large")
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
Salida{
'solutions': ["D F L' F' U2 B2 U F' L R2 B2 U D' F2 U2 R D'"],
'num_nodes': 903448,
'time': 20.46845487099995
}
Aplicando Sesgo Ergonómico
Para encontrar soluciones que sean más fáciles de ejecutar manualmente, proporciona un diccionario ergonomic_bias al método solve.
A cada movimiento se le asigna una puntuación, donde las puntuaciones más altas indican movimientos más deseables. Esto también habilita movimientos amplios como u y r.
ergonomic_bias = {
"U": 0.9, "U'": 0.9, "U2": 0.8,
"R": 0.8, "R'": 0.8, "R2": 0.75,
"L": 0.55, "L'": 0.4, "L2": 0.3,
"F": 0.7, "F'": 0.6, "F2": 0.6,
"D": 0.3, "D'": 0.3, "D2": 0.2,
"B": 0.05, "B'": 0.05, "B2": 0.01,
"u": 0.45, "u'": 0.45, "u2": 0.4,
"r": 0.3, "r'": 0.3, "r2": 0.25,
"l": 0.2, "l'": 0.2, "l2": 0.15,
"f": 0.35, "f'": 0.3, "f2": 0.25,
"d": 0.15, "d'": 0.15, "d2": 0.1,
"b": 0.03, "b'": 0.03, "b2": 0.01
}
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
ergonomic_bias=ergonomic_bias
)
print(result)
Salida{
'solutions': [
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R U L' U R L",
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R d F' U f F",
"u' U' f' R2 U2 R' L' F' R u2 F2 R2 D2 R u f' l u U"
],
'num_nodes': 1078054,
'time': 56.13087955299852
}
Modelos y Compromisos
AlphaCube ofrece tres modelos entrenados de forma computacionalmente óptima del artículo original: "small", "base" y "large".
Aunque los modelos más grandes son más precisos, la mejor elección depende de tu hardware.
- En una CPU, el modelo
"small"suele ser la opción más eficiente en cuanto a tiempo. - En una GPU, el modelo
"large"muestra el mayor rendimiento y encuentra las mejores soluciones en el menor tiempo.
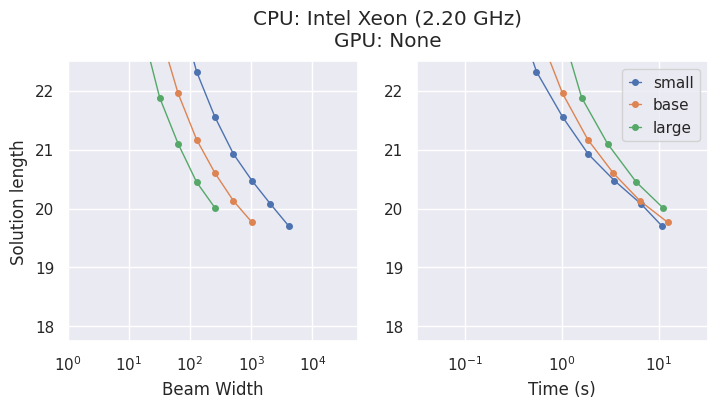
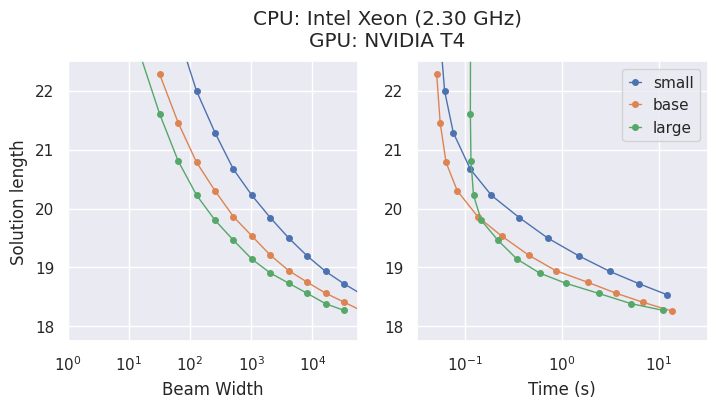
Opción de CLI
Si prefieres usar alphacube desde la línea de comandos, puedes hacerlo así:
alphacube \
--model_id large \
--scramble "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
--beam_width 100000 \
--extra_depths 3 \
--verbose
Con indicadores abreviados,
alphacube \
-m large \
-s "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
-bw 100000 \
-ex 3 \
-v
Puedes encontrar más detalles en Referencia de la API > CLI.
Nota: La CLI carga el modelo especificado en cada ejecución, lo que la hace más adecuada para comandos de un solo uso en lugar de para la resolución repetida en un script.