Erste Schritte
Installation
Um AlphaCube zu installieren, öffnen Sie ein Terminal und führen Sie den folgenden Befehl aus:
pip install -U alphacube
Verwendung
Grundlagen
Die Verwendung von AlphaCube in Python ist einfach. Wenn alphacube.load() zum ersten Mal aufgerufen wird, werden die erforderlichen Modelldaten heruntergeladen und zwischengespeichert.
import alphacube
# Ein vortrainiertes Modell laden
# Standardmäßig "small" auf CPU, "large" auf GPU
alphacube.load()
# Den Würfel mit einem gegebenen Scramble lösen
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=1024,
)
print(result)
Ausgabe{
'solutions': [
"D L D2 R' U2 D B' D' U2 B U2 B' U' B2 D B2 D' B2 F2 U2 F2"
],
'num_nodes': 19744, # Gesamtzahl der durchsuchten Suchknoten
'time': 1.4068585219999659 # Zeit in Sekunden
}
Lösungsqualität verbessern
Wenn Sie kürzere Lösungen wünschen, erhöhen Sie den Parameter beam_width.
Dies macht die Suche auf Kosten von mehr Rechenzeit erschöpfender.
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
Ausgabe{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'"
],
'num_nodes': 968984,
'time': 45.690575091997744
}
Einige zusätzliche Züge erlauben
Mit dem Parameter extra_depths können Sie nicht nur die kürzesten, sondern auch etwas längere Lösungen erhalten.
Dies weist den Löser an, die Suche fortzusetzen, nachdem die erste Lösung gefunden wurde.
alphacube.load() # model_id="small"
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
extra_depths=1
)
print(result)
Ausgabe{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'",
"D R F2 L' U2 R2 U2 R2 B2 U' F B2 D' F' D' R2 F2 U F2 L2", # zusätzlich
"L' D' R' D2 L B' U F2 U R' U' F B' R2 B R B2 F D2 B", # zusätzlich
"R' F L2 D R2 U' B' L' U2 F2 U L U B2 U2 R2 D' U B2 R2", # zusätzlich
"L' U' F' R' U D B2 L' B' R' B U2 B2 L2 D' R2 U' D R2 U2" # zusätzlich
],
'num_nodes': 1100056,
'time': 92.809575091997744
}
GPU-Beschleunigung
Wenn Sie eine kompatible GPU oder einen Mac haben, können Sie durch das Laden eines large-Modells eine erhebliche Beschleunigung erzielen.
alphacube.load(model_id="large")
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
Ausgabe{
'solutions': ["D F L' F' U2 B2 U F' L R2 B2 U D' F2 U2 R D'"],
'num_nodes': 903448,
'time': 20.46845487099995
}
Ergonomische Gewichtung anwenden
Um Lösungen zu finden, die manuell einfacher auszuführen sind, übergeben Sie ein ergonomic_bias-Wörterbuch an die solve-Methode.
Jedem Zug wird eine Punktzahl zugewiesen, wobei höhere Punktzahlen wünschenswertere Züge anzeigen. Dies ermöglicht auch breite Züge wie u und r.
ergonomic_bias = {
"U": 0.9, "U'": 0.9, "U2": 0.8,
"R": 0.8, "R'": 0.8, "R2": 0.75,
"L": 0.55, "L'": 0.4, "L2": 0.3,
"F": 0.7, "F'": 0.6, "F2": 0.6,
"D": 0.3, "D'": 0.3, "D2": 0.2,
"B": 0.05, "B'": 0.05, "B2": 0.01,
"u": 0.45, "u'": 0.45, "u2": 0.4,
"r": 0.3, "r'": 0.3, "r2": 0.25,
"l": 0.2, "l'": 0.2, "l2": 0.15,
"f": 0.35, "f'": 0.3, "f2": 0.25,
"d": 0.15, "d'": 0.15, "d2": 0.1,
"b": 0.03, "b'": 0.03, "b2": 0.01
}
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
ergonomic_bias=ergonomic_bias
)
print(result)
Ausgabe{
'solutions': [
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R U L' U R L",
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R d F' U f F",
"u' U' f' R2 U2 R' L' F' R u2 F2 R2 D2 R u f' l u U"
],
'num_nodes': 1078054,
'time': 56.13087955299852
}
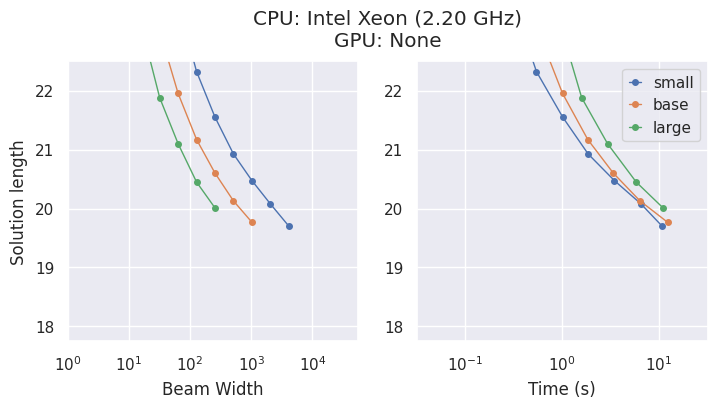
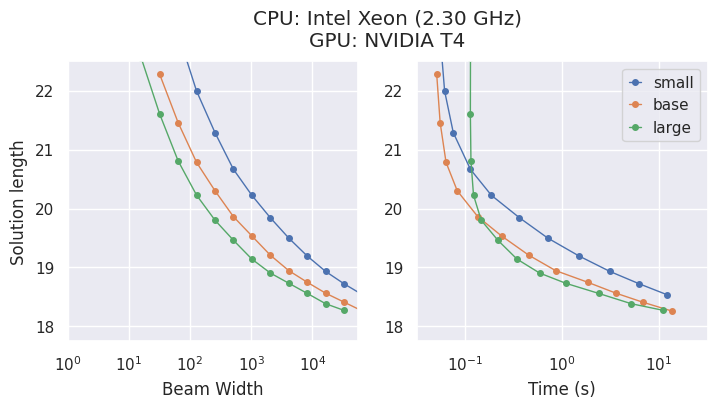
Modelle & Kompromisse
AlphaCube bietet drei rechenoptimal trainierte Modelle aus dem Originalartikel: "small", "base" und "large".
Größere Modelle sind zwar genauer, die beste Wahl hängt jedoch von Ihrer Hardware ab.
- Auf einer CPU ist das
"small"-Modell oft die zeiteffizienteste Wahl. - Auf einer GPU zeigt das
"large"-Modell die höchste Leistung und findet die besten Lösungen in der kürzesten Zeit.
CLI-Option
Wenn Sie alphacube lieber über die Kommandozeile verwenden, können Sie dies tun:
alphacube \
--model_id large \
--scramble "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
--beam_width 100000 \
--extra_depths 3 \
--verbose
Mit abgekürzten Flags,
alphacube \
-m large \
-s "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
-bw 100000 \
-ex 3 \
-v
Weitere Details finden Sie unter API-Referenz > CLI.
Hinweis: Die CLI lädt das angegebene Modell bei jeder Ausführung, wodurch sie sich am besten für einmalige Befehle eignet und nicht für wiederholtes Lösen in einem Skript.