はじめに
インストール
AlphaCubeをインストールするには、ターミナルを開いて次のコマンドを実行します:
pip install -U alphacube
使い方
基本的な使い方
PythonでAlphaCubeを使うのは簡単です。最初に alphacube.load() を呼び出すと、必要なモデルデータがダウンロードされ、キャッシュされます。
import alphacube
# 事前学習済みモデルを読み込む
# CPUでは "small"、GPUでは "large" がデフォルト
alphacube.load()
# 与えられたスクランブルでキューブを解く
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=1024,
)
print(result)
出力{
'solutions': [
"D L D2 R' U2 D B' D' U2 B U2 B' U' B2 D B2 D' B2 F2 U2 F2"
],
'num_nodes': 19744, # 探索した総ノード数
'time': 1.4068585219999659 # 処理時間(秒)
}
解の質を向上させる
より短い手数で解きたい場合は、beam_width パラメータを増やしてください。
これにより、計算時間は増えますが、より徹底的な探索が行われます。
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
出力{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'"
],
'num_nodes': 968984,
'time': 45.690575091997744
}
少し長い手数も許容する
最短解だけでなく、少しだけ手数の長い解も得たい場合は、extra_depths パラメータを使用します。
これにより、最初の解が見つかった後も探索を続けるようソルバーに指示します。
alphacube.load() # model_id="small"
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
extra_depths=1
)
print(result)
出力{
'solutions': [
"D' R' D2 F' L2 F' U B F D L D' L B D2 R2 F2 R2 F'",
"D2 L2 R' D' B D2 B' D B2 R2 U2 L' U L' D' U2 R' F2 R'",
"D R F2 L' U2 R2 U2 R2 B2 U' F B2 D' F' D' R2 F2 U F2 L2", # 追加解
"L' D' R' D2 L B' U F2 U R' U' F B' R2 B R B2 F D2 B", # 追加解
"R' F L2 D R2 U' B' L' U2 F2 U L U B2 U2 R2 D' U B2 R2", # 追加解
"L' U' F' R' U D B2 L' B' R' B U2 B2 L2 D' R2 U' D R2 U2" # 追加解
],
'num_nodes': 1100056,
'time': 92.809575091997744
}
GPUアクセラレーション
互換性のあるGPUまたはMacをお持ちの場合、large モデルを読み込むことで大幅な高速化が可能です。
alphacube.load(model_id="large")
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
)
print(result)
出力{
'solutions': ["D F L' F' U2 B2 U F' L R2 B2 U D' F2 U2 R D'"],
'num_nodes': 903448,
'time': 20.46845487099995
}
人間工学に基づいたバイアスを適用する
手で回しやすい解を見つけるには、solve メソッドに ergonomic_bias 辞書を渡します。
各操作にスコアが割り当てられ、スコアが高いほど望ましい操作であることを示します。これにより、u や r のようなワイドムーブも有効になります。
ergonomic_bias = {
"U": 0.9, "U'": 0.9, "U2": 0.8,
"R": 0.8, "R'": 0.8, "R2": 0.75,
"L": 0.55, "L'": 0.4, "L2": 0.3,
"F": 0.7, "F'": 0.6, "F2": 0.6,
"D": 0.3, "D'": 0.3, "D2": 0.2,
"B": 0.05, "B'": 0.05, "B2": 0.01,
"u": 0.45, "u'": 0.45, "u2": 0.4,
"r": 0.3, "r'": 0.3, "r2": 0.25,
"l": 0.2, "l'": 0.2, "l2": 0.15,
"f": 0.35, "f'": 0.3, "f2": 0.25,
"d": 0.15, "d'": 0.15, "d2": 0.1,
"b": 0.03, "b'": 0.03, "b2": 0.01
}
result = alphacube.solve(
scramble="D U F2 L2 U' B2 F2 D L2 U R' F' D R' F' U L D' F' D R2",
beam_width=65536,
ergonomic_bias=ergonomic_bias
)
print(result)
出力{
'solutions': [
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R U L' U R L",
"u' U' f' R2 U2 R' L' F' R D2 f2 R2 U2 R d F' U f F",
"u' U' f' R2 U2 R' L' F' R u2 F2 R2 D2 R u f' l u U"
],
'num_nodes': 1078054,
'time': 56.13087955299852
}
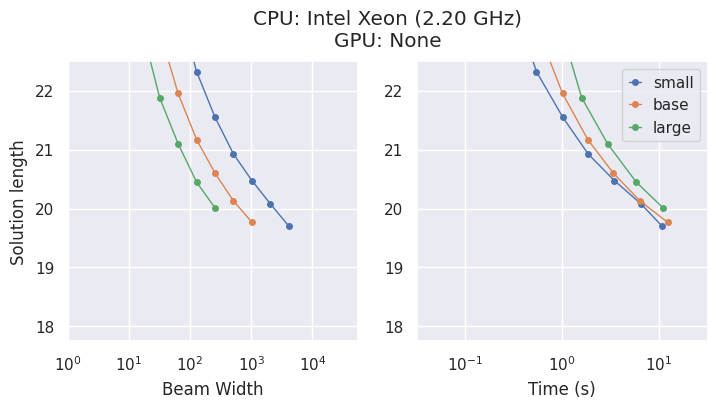
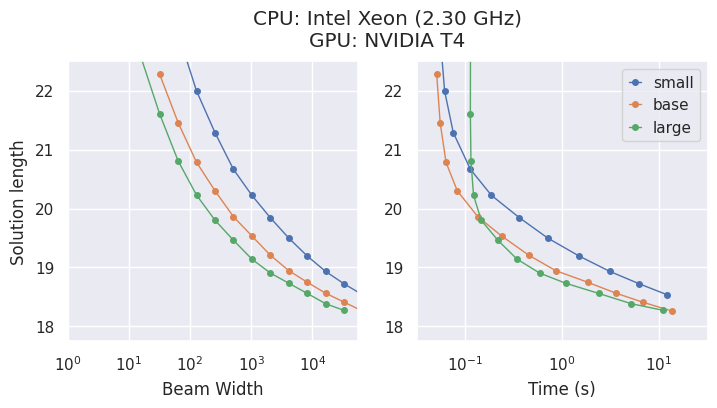
モデルとトレードオフ
AlphaCubeは、原論文で発表された計算量的に最適化された3つの学習済みモデルを提供します:"small"、"base"、"large"です。
大規模なモデルほ��ど精度は高くなりますが、最適な選択はハードウェアに依存します。
- CPUでは、
"small"モデルが最も時間効率の良い選択となることが多いです。 - GPUでは、
"large"モデルが最高のパフォーマンスを発揮し、最短時間で最良の解を見つけます。
CLIオプション
alphacube をコマンドラインから使用したい場合は、次のように実行できます:
alphacube \
--model_id large \
--scramble "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
--beam_width 100000 \
--extra_depths 3 \
--verbose
省略形のフラグを使用した場合、
alphacube \
-m large \
-s "F U2 L2 B2 F U L2 U R2 D2 L' B L2 B' R2 U2" \
-bw 100000 \
-ex 3 \
-v
詳細については、APIリファレンス > CLI を参照してください。
注意: CLIは実行のたびに指定されたモデルを読み込みます。そのため、スクリプト内で繰り返し解を求めるのではなく、単発のコマンド実行に適しています。